第一章:数据库体系结构
点击数:1453发布日期:2020-04-19 14:35:20 来源:老鹰
第一章:数据库体系结构
学习Oracle数据库,一开始就是学习Oracle历史,体系结构。我们先来看一下Oracle历史,再来看体系结构。
1.1 Oracle 历史
Oracle一开始是从军用开始,军方要研发一个存放数据的软件,名为Oracle。埃里森是其中的程序员。
后来他觉得民用也会有市场,于是1977年埃里森和同事成立软件开发实验室,开发出了新版本的Oracle数据库。
1978年公司迁往硅谷,更名为RSI关系软件公司,开发出了商用Oracle数据库。这个数据库整合了查询功能,表连接等其它一些特性。美国的中央情报局想买一套有这样功能的软件,先找IBM买,但IBM没有这种软件。于是联系了RSI,Oracle也就有了第一个客户。
经过几次的改名,1982年最终把公司名改为Oracle。
Oracle 1989年进入中国,1991年在北京成立甲骨文中国公司。
后来中国电信行业采用了Oracle数据库,一下子就起来了。再向后,金融行业,政府机关也采用Oracle数据库,在中国就发展起来了。
Oracle理念是最初版本让大家随便用,软件随便下载,很容易就能得到它的安装介质,练习实验很方便,等大家用的多了,用的顺手了,再卖license圈钱。
但软件补丁得要服务账号才能下载到,下载补丁把数据库升级至最稳定的版本之后,数据库产品才可以高枕无忧,否则使用最初发行的版本,bug多的像天上的星星,系统压力一大,根本无法使用。这种方法,也可以控制一部分盗版。
让20%的人付80%的钱,二八定律。Oracle软件授权卖的很贵,按CPU或按用户数卖,让大用户,大公司付高昂的license费用。同时也有部门面向小用户,个人学习培训等小单子。
1.2 Oracle 体系结构
Oracle体系结构,就是这一张图。RAC和12c的体系结构就是在这一张图上有所扩展,其根本还是这一张图。只要我们把这一张图搞明白了,事半功倍。
我们按照从左到右从上到下的顺序,介绍一遍这一张图。
用户端进程,User Process:相当于你的台式机或笔记本电脑或中间件服务器产生的一个进程,要和数据库服务器产生连接,形成一个通道。这个在客户端的进程叫用户进程。用户进程不直接和数据库交互,它通过和服务器进程建立的session和数据库交互。
服务器进程,Server Process:在服务器端,和用户进程进行对话的进程叫服务器进程。在linux,unix平台上,服务器进程有很多,共享服务模式下,和用户端进程是一一对应的关系。一个服务员专门为一个顾客服务,所以服务质量比较好,速度比较快。在windows环境下,是单进程分出多个线程,线程没有进程速度快,内存利用不如进程使用的充分,因此核心库在windows下的较少。
会话,Session:用户端进程和服务器进程建立的这个通路,就叫一个会话,像水管,负责来回运送用户端和服务器端的数据。不管是进程还是会话,都是用肉眼看不到的,我们可以用命令查看它们,它们的状态,参数,说明都可以用命令查询到。
程序全局区,PGA (Process Global Area) ,进程专用的内存区域,不共享。用来排序的,如果数据库的排序工作很多在磁盘上完成,那么证明PGA设小了。还有权限控制的功能。一般设置几GB十几GB,具体看数据库排序工作的多少。如果没有磁盘排序,就证明够用。在实例启动时分配,但不是按参数设置的大小分配,是按实际需求的大小分配。
实例,Instance:实例不叫数据库,实例是由一大块内存区域和后台进程组成。也可以说实例包含SGA和后台进程。实例的特点是运算速度快,数据交换速度快,减少I/O的访问,相当于货运集散地,物流中心。关闭数据库之后,实例就什么都没了。
系统全局区,SGA (System Global Area):是实例的基本组成部分,是一块内存区域,是被进程共享的,不会独占,由数据高速缓冲区、共享池、重做日志缓冲区、大池、java池、流池(Streams Pool)组成。最好手工管理其大小,压力较小的情况下,自动管理也可以。
共享池,Shared Pool:共享池存放最近最常使用的SQL语句和最近最常使用的数据字典信息。当然常用的程序包,存储过程也可以在里面,还可以手工keep到里面,不出来。
库缓冲区,Library Cache,存放最近最常使用的SQL语句,被解析的结果也存放在里面,如果使用了绑定变量,下一次再执行同样的SQL时,就不需要硬解析了,直接使用解析好的执行计划,省去了硬解析过程,节约CPU等资源。
数据字典缓冲区,Data Dictionary Cache:存放最近最常使用的数据库定义,数据库自身的一些表,也包括对应用用户表,列,权限,索引及其它对象的定义。
数据块高速缓冲区,Database Buffer Cache:是instance中最大的一块内存区域,内存手工管理的情况下,由参数db_cache_size来设置。它的大小,直接影响I/O的多少,所以我们应该认真研究db_cache_size的设置。
重做日志缓冲区,Redo Log Buffer:相当于一个漏斗,大小很小,由LGWR进程写入redo log。每次写的数据量比较小,但写的很频繁,所以就要求redo log必须放在速度快的磁盘上。大小由参数log_buffer来设置。
后台进程:实例的组成部分,相当于一个个的水管,说它是搬运工也很贴切,保持物理数据库和内存结构的关系,分为必须的后台进程和可选后台进程。必须的后台进程是DBWR,PMON,CKPT,LGWR,SMON,RECO六个。可选的后台进程有:ARCn,LMON,Snnn,QMNn,LMDn,CJQ0,Pnnn,LCKn,Dnnn。
数据库写进程DBWR (Database Writer Process):将buffer cache中的脏块写入数据文件,脏块指的是被修改的数据块。遵循LRU算法,写最近最少使用的块。在以下情况下开始写:1、执行检查点2、脏块数达到上限3、缓存没有自由空间4、超时5、连接RAC要求6、表空间offline 7、表空间read only 8、清空和删除表9、表空间开始备份。
进程监控进程PMON (Process Monitor):有一种鱼叫清道夫,清除水中的垃圾,PMON就是这种进程。清除失效的用户进程,释放用户进程所用的资源,将未完成的事务回滚,释放锁,释放其它资源,重启死的dispathchs。
检查点进程CKPT (Checkpoint Process):更新数据文件头,同步数据文件、日志文件和控制文件。给DBWR发信号,修改控制文件。
日志写进程LGWR (Log Writer):将log buffer中的数据写入redo logfile。在以下情况下开始写:1、提交时2、每隔三秒钟3、在DBWR写之前4、达到阀值。日志写进程的触发条件根据版本的不同会有所变化,所以log buffer的设置也有一些变数。
系统监控进程SMON (System Monitor):负责清理临时空间,实例恢复,收缩undo段。
分布式恢复进程RECO (Distributed Recovery):自动的解决在分布式事务中悬而未决的事务。
以上这些是单机版的后台进程,RAC的后台进程包含单机版的后台进程,RAC的后台进程,我们在之后的章节叙述。再向下看。
参数文件spfile或pfile:两种参数文件可以相互转换,系统默认使用spfile,如果没有spfile,再去找pfile。参数文件的位置unix、linux系统在ORACLE_HOME/dbs底下,windows操作系统在ORACLE_HOME/database底下,采用ASM管理文件时,spfile通过initsid.ora指向ASM里面。参数文件是记录instance参数的文件。spfile是二进制格式,pfile是文本文件格式。spfile必须使用alter system命令修改,有些参数可以在线修改即生效,不需要重启数据库。pfile只能使用编辑器修改参数,必须重启数据库生效。spfile是pfile的升级版,8i和8i之前只有pfile,9i才引入spfile。
密码文件orapwsid文件:位置在ORACLE_HOME/dbs下,windows操作系统在ORACLE_HOME/database下,和spfile在一个文件夹底下。主要作用是认证通过或拒绝DBA身份的人连接到数据库里去。使用或不使用密码文件通过数据库参数remote_login_passwordfile来设置。以DBA身份登录数据库有两种方法,一是操作系统认证登录,不使用密码文件;二是密码文件认证登录数据库。启用或关闭操作系统认证使用$ORACLE_HOME/network/admin/sqlnet.ora文件里的参数sqlnet.authentication_services。当此参数设置为none时,将关闭操作系统认证。此文件和以上设置是提高Oracle数据库安全的一种方法。
数据库database:从专业的角度讲,也就是业内人士的称谓,数据库只包含三种文件即:数据文件,控制文件,日志文件,其它所有文件都不叫数据库。这三种数据文件缺一不可,缺少任何一种文件数据库都无法正常运行。组成一个数据库至少需要四个文件即:一个数据文件,一个控制文件,两个日志文件。
数据文件datafile:存放数据对象的操作系统物理文件,是数据库中最大的一种文件。我们的表,索引,数据字典,程序等等对象都在数据文件中存放。相当于一个仓库。一个数据文件只能属于一个表空间,一个表空间可以包含一个或多个数据文件。数据文件包含段、区、块。段区块的设置也影响数据库的性能。如我们OLAP的数据库,我们可以使用32KB的块,提高读取的效率。
控制文件controlfile:控制文件是一个比较小的二进制文件,大小一般为10MB左右,大小基本不变。存放数据库的物理结构,如数据库名,数据文件在什么地方,日志文件的名称和位置,备份信息,检查点信息等。控制文件的位置在参数文件中记录。我们一般要复用两份或三份来保护控制文件。控制文件类似于书的目录或家里的管家。
重做日志文件redolog:相当于录影带,记录数据文件所有的变化。如果数据文件丢失,我们只需要有一份全备,再加上归档日志和在线日志,就可以做数据库的全恢复,做到一条数据也不丢。日志文件大小不变,改变它的大小只能添加新的删除旧的。它的写速度对性能的影响非常大。因为在线日志文件的大小不变,在归档模式下,写满之后,就自动cp一份生成归档日志文件。
归档日志文件archivelog:归档日志是重做日志的cope。大小等于或小于重做日志文件。它的主要做用是用于恢复数据库。数据库恢复的时候必须有备份,归档日志才有意义,没有备份,光有归档日志没用,由此看出数据库全备的重要性。归档日志文件必须定期删除,否则早晚会把空间撑满,把数据库hang住,一般在做完备份后删除,具体的删除策略要结合备份策略来制定。
SQL执行流程:终端用户点一下鼠标或执行一个动作,可能产生一条SQL语句或一段PLSQL程序,从此这条SQL语句就开始了一个“漫长的”执行过程,我们假设用户要执行一个查询语句。用户进程user process首先要通过listener在验证用户名和密码无误之后和server process建立一个session,通过这个session将SQL语句放入共享池中的library cache,先从中找有没有这条语句的执行计划,如果没有则要硬解析生成执行计划,有了执行计划就知道了怎么执行这条SQL语句,将在buffer cache中查找有没有想要的数据,如果有直接返回给用户,如果没有则要通过物理I/O在数据文件中读取,读出来之后返回给用户,这条查询语句就执行完了。
1.3 10g11g RAC体系结构
在12c之前,一个实例只能打开一个数据库,一个数据库可以被多个实例打开。一个数据库一个实例就是单机版数据库,一个数据库多个实例就是RAC。RAC一般2个节点,也可以做成4节点6节点8节点,单数节点也可以,但不建议使用太多的节点,节点多可能出故障的几率会增加,管理维护成本也会增加。在本书中所涉及的RAC都是两个节点。和单机版功能相同的组件我们就不叙述了,我们只讲RAC独有的组件。
RAC (Real Application Clusters),真正的应用集群。其目的是为了防止主机损坏,和CPU不够用,对于存储损坏,RAC无能为力。RAC一般由多台主机一台存储组成,每台主机上都有自己的监听器,监听自己的网络端口,每台主机都有自己的集群就绪服务,用于集群管理。所有的主机通过自己的操作系统访问同一个存储,共享的存储10g设备可以是集群文件系统(OCFS),ASM(自动存储管理),裸设备(RAW)或网络区域存储(NAS)。到了11g第二版,淘汰了裸设备,增强了ASM的功能,共享存储只能使用ASM和共享文件系统了。
在图中没有体现voting disk和OCR盘,这两种也是非常重要的共享文件。在10g时,这两种文件必须放在裸设备上或OCFS上,不能放在ASM上,到了11g第二版,voting disk和OCR盘可以放在ASM上了,大大方便了存储的划分,所以注定10g成为过渡版本,11g第二版才更加成熟。
Oracle集群注册表OCR(Oracle Cluster Register):OCR盘记录节点配置信息,CRS包含的资源数据库,实例,监听器,ASM,VIP等配置信息都在OCR中记录。CRS进程读取OCR盘来获取信息,所以CRS进程起不来很多命令执行不了,srvctl,dbca,dbua,netca,crs_stat都无法执行RAC操作,因为这些程序都是CRS的客户端。OCR盘的大小约为100MB。Oracle每隔三个小时自动备份一次OCR盘,保留最后的三份。
[root@yingshu1 bin]# ./ocrconfig -showbackup
yingshu1 2015/09/17 11:31:09 /u01/11.2.0/grid/cdata/yingshu-cluster/backup00.ocr
yingshu1 2015/09/16 18:31:27 /u01/11.2.0/grid/cdata/yingshu-cluster/backup01.ocr
yingshu1 2015/09/16 14:31:26 /u01/11.2.0/grid/cdata/yingshu-cluster/backup02.ocr
yingshu1 2015/09/16 14:31:26 /u01/11.2.0/grid/cdata/yingshu-cluster/day.ocr
yingshu1 2015/09/04 13:53:34 /u01/11.2.0/grid/cdata/yingshu-cluster/week.ocr
可以使用以下命令对OCR进行恢复。恢复时CRS必须停止。
[root@yingshu1 bin]# pwd
/u01/11.2.0/grid/bin
[root@yingshu1 bin]# ./ocrconfig -restore /u01/11.2.0/grid/cdata/yingshu-cluster/backup00.ocr
检查当前OCR的状态。
[root@yingshu1 bin]# ./ocrcheck
Status of Oracle Cluster Registry is as follows :
Version : 3
Total space (kbytes) : 262120
Used space (kbytes) : 3056
Available space (kbytes) : 259064
ID : 261064960
Device/File Name : +OGOCR
Device/File integrity check succeeded
Device/File not configured
Cluster registry integrity check succeeded
Logical corruption check succeeded
投票盘Voting Disk:记录节点成员信息,如包含哪些节点成员,节点的添加删除信息。voting disk的主要作用是在发生脑裂时,决定由哪个节点获取控制权,踢除其它节点,voting disk采用多数可用算法,超过一半的voting disk可以使用时,集群才可以正常运行。所以voting disk的个数建议是1个,3个,5个。不建议是2个或4个,如果是2个,一个也不能坏,如果是4个只能坏一个。
[root@yingshu1 bin]# ./crsctl query css votedisk
## STATE File Universal Id File Name Disk group
-- ----- ----------------- --------- ---------
1. ONLINE 9be94b2e72ab4f30bfff452502b37981 (/dev/raw/raw1) [OGOCR]
Located 1 voting disk(s).
[root@yingshu1 bin]#
RAC的组成:
1、cluster nodes需要2到n个节点运行CRS软件及数据库软件。集群和数据库软件一般都安装在主机本地。10g集群和数据库软件都由Oracle用户来安装。11g引入grid用户,grid只负责集群软件,Oracle用户只负责数据库软件。
2、私有网络,10g每个主机至少需要两张网卡,每个主机至少需要设置3个IP地址。11g每台主机至少需要两张网卡,每台主机至少需要设置4个IP地址,比10g多一个SCAN IP地址。两个节点的SCAN IP地址是一样的,为的是单一节点访问,提供服务的只需要一个IP就可以了。
3、共享存储,让所有节点都可以读写的存储设备,多路径需要做好。
4、对外服务的网络,我们可以把vip做为对外服务的IP地址,也可以用SCAN IP做为对外服务的IP地址,具体看规划,甚至public IP也可以提供服务。
RAC的主要组件:
1、服务器大于或等于2台。
2、操作系统,推荐使用Oracle认证的操作系统,aix,hp-ux,linux。不建议用windows。
3、CPU/内存。建议CPU8核以上,内存32GB以上。
4、本地磁盘大于60GB。
5、网卡至少2张,建议3张或4张,两张绑成一张做为私有网卡内部通信使用。如果只有三张,那么绑内部通信的私有网络,不绑公用网络。如果4张网卡,可以都绑。
6、私有以太网,建议千MB以上,网线不建议两台主机直连,建议都接在交换机上速度更快更稳定。
7、共享存储,推荐使用SAN设备。
8、HBA卡,如果使用SAN设备,推荐两个HBA卡。
9、存储管理,ASM,共享文件系统,裸设备。10g可以使用裸设备,11g一般用ASM。
10、集群管理软件,10g是OCR软件,11g是grid软件。
RAC的主要后台进程:
[root@yingshu1 grid]# ps -ef|grep d.bin
root 4537 1 0 Sep16 ? 00:01:14 /u01/11.2.0/grid/bin/ohasd.bin reboot
grid 5200 1 0 Sep16 ? 00:00:18 /u01/11.2.0/grid/bin/gpnpd.bin
grid 5216 1 0 Sep16 ? 00:01:17 /u01/11.2.0/grid/bin/gipcd.bin
root 5230 1 0 Sep16 ? 00:02:19 /u01/11.2.0/grid/bin/osysmond.bin
root 5251 1 0 Sep16 ? 00:00:10 /u01/11.2.0/grid/bin/cssdmonitor
root 5293 1 0 Sep16 ? 00:00:09 /u01/11.2.0/grid/bin/cssdagent
grid 5318 1 0 Sep16 ? 00:01:28 /u01/11.2.0/grid/bin/ocssd.bin
root 5744 1 0 Sep16 ? 00:00:17 /u01/11.2.0/grid/bin/octssd.bin reboot
grid 5805 1 0 Sep16 ? 00:00:17 /u01/11.2.0/grid/bin/evmd.bin
root 7001 1 0 Sep16 ? 00:00:59 /u01/11.2.0/grid/bin/crsd.bin reboot
高可用服务守护进程:ohasd (Oracle High Availability Services Daemon) Oracle集群资源底层主持进程。是11gR2 RAC的关键进程,包含多个帮助操作集群的进程。
集群就绪服务守护进程:crsd(Cluster Ready Services Daemon) 主要的集群进程,执行高可用恢复和管理操作。如维护OCR,管理应用资源,在失败的时候重启应用资源。是Oracle 10g核心进程,包含数据库、实例、监听、VIP,ons,gds等资源。出故障的时候,操作系统会重启这个进程。此进程由root用户负责启动和关闭。这个进程起不来,srvctl等命令执行不了。
集群同步服务进程:cssd(Cluster Synchronization Services Daemon) 一个linux,unix系统中的进程,管理集群同步服务,负责各节点间的通信。节点在加入或离开集群时通知集群,发生故障时cssd也会重启系统。
事件监测进程:evmd(Event Manager Daemon)事件管理进程,负责发布crs的各种事件。
RAC的主要警告日志: Oracle RAC的警告日志在grid用户,CRS_HOME/log/sid下。如果发生进程无法启动,RAC出现故障等情况,可以查看对应的某个进程的日志。本书中安装的RAC,日志在yingshu1 下。文件夹的名称就是进程名,进入文件夹后,即可查看这个进程的日志,由此对故障做出详细的判断。
[grid@yingshu1 yingshu1]$ pwd
/u01/11.2.0/grid/log/yingshu1
[grid@yingshu1 yingshu1]$ ls
acfs acfsreplroot agent crflogd cssd diskmon gnsd ohasd
acfslog acfssec alertyingshu1.log crfmond ctssd evmd gpnpd racg
acfsrepl admin client crsd cvu gipcd mdnsd srvm
由于编者水平有限,书中难免存在疏漏之处,敬请各位专家和读者批评指正,作者的E-mail:fupeili@163.com QQ:535000791 电话:133 8102 9910感谢您使用本教材,期待本教材能成为您的良师益友。
下一篇:第三章:数据库系统的规划
图文推荐
 序言
序言
2020-04-19 查看:3354
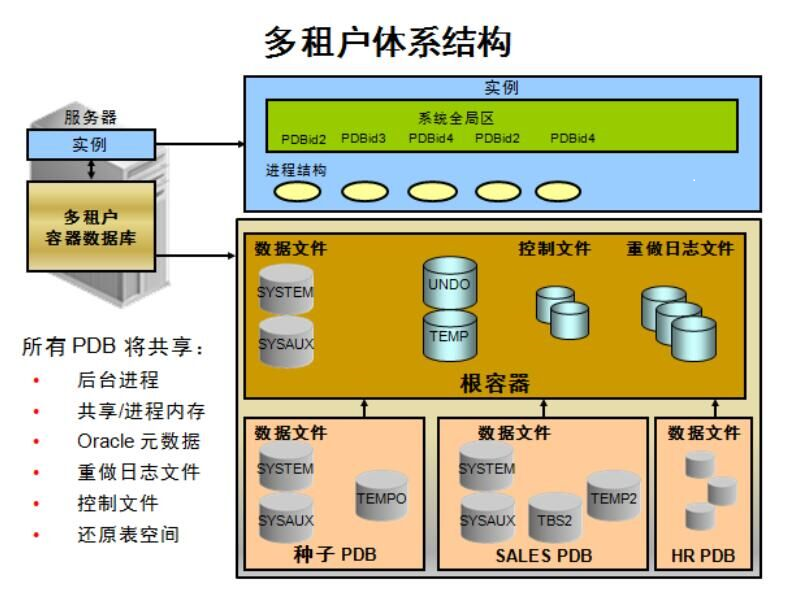 第十五章:Oracle 12c介绍
第十五章:Oracle 12c介绍
2020-04-19 查看:3259
 第十四章:常用Oracle工具
第十四章:常用Oracle工具
2020-04-19 查看:2926
 第十三章:Oracle Golde...
第十三章:Oracle Golde...
2020-04-19 查看:3205
 第十二章:DataGuard
第十二章:DataGuard
2020-04-19 查看:2738
